


Effortless OCR: Simple Guide to Process Documents with AWS Textract
A Simple Guide to AWS Textract


In today's digital age, there's a growing need for extracting information from documents, leading to the rise of Optical Character Recognition (OCR) technology. OCR makes it possible to convert scanned paper documents, PDF files, or images from digital cameras into editable and searchable data. Whether you prefer free options or premium services, there are many choices available to meet your needs.
Open-Source Solutions
There are several open-source OCR models known for their flexibility and accessibility:
Google’s Tesseract: Highly accurate and supported by Google, Tesseract is a strong choice with extensive documentation and a supportive community.
EasyOCR: Developed by Jaided AI, EasyOCR is praised for its ease of use and great performance across many languages, making it a popular pick for various projects.
Paddle OCR: Powered by PaddlePaddle, Paddle OCR is efficient and adaptable, offering strong support for text detection and recognition tasks.
and more...
Paid Solutions
For businesses in need of premium OCR solutions, there are several paid services available:
AWS Textract: Amazon Web Services (AWS) Textract offers advanced OCR features seamlessly integrated into the AWS ecosystem, including automatic document detection and intelligent data extraction.
Google Document AI: Leveraging Google's advanced AI, Document AI provides precise text extraction and semantic analysis for valuable insights from documents.
Azure AI Vision: Microsoft Azure AI Vision provides a range of OCR tools for text extraction, object detection, and image analysis, offering scalable solutions tailored to diverse business needs.
and more...
Choosing the Right Solution
Choosing between open-source OCR models and paid services depends on factors like project needs, budget, and desired features. Open-source options offer flexibility and community support, while paid services provide comprehensive features, reliability, and professional assistance. By assessing your requirements and comparing the strengths of each option, you can make a well-informed decision that matches your goals.
Analyzing Documents with AWS Textract
In case you are interested in how Textract works read more here
With Textract, you can effortlessly extract relevant information from documents, just like interacting with a human. Consider the following example of analyzing a health card:
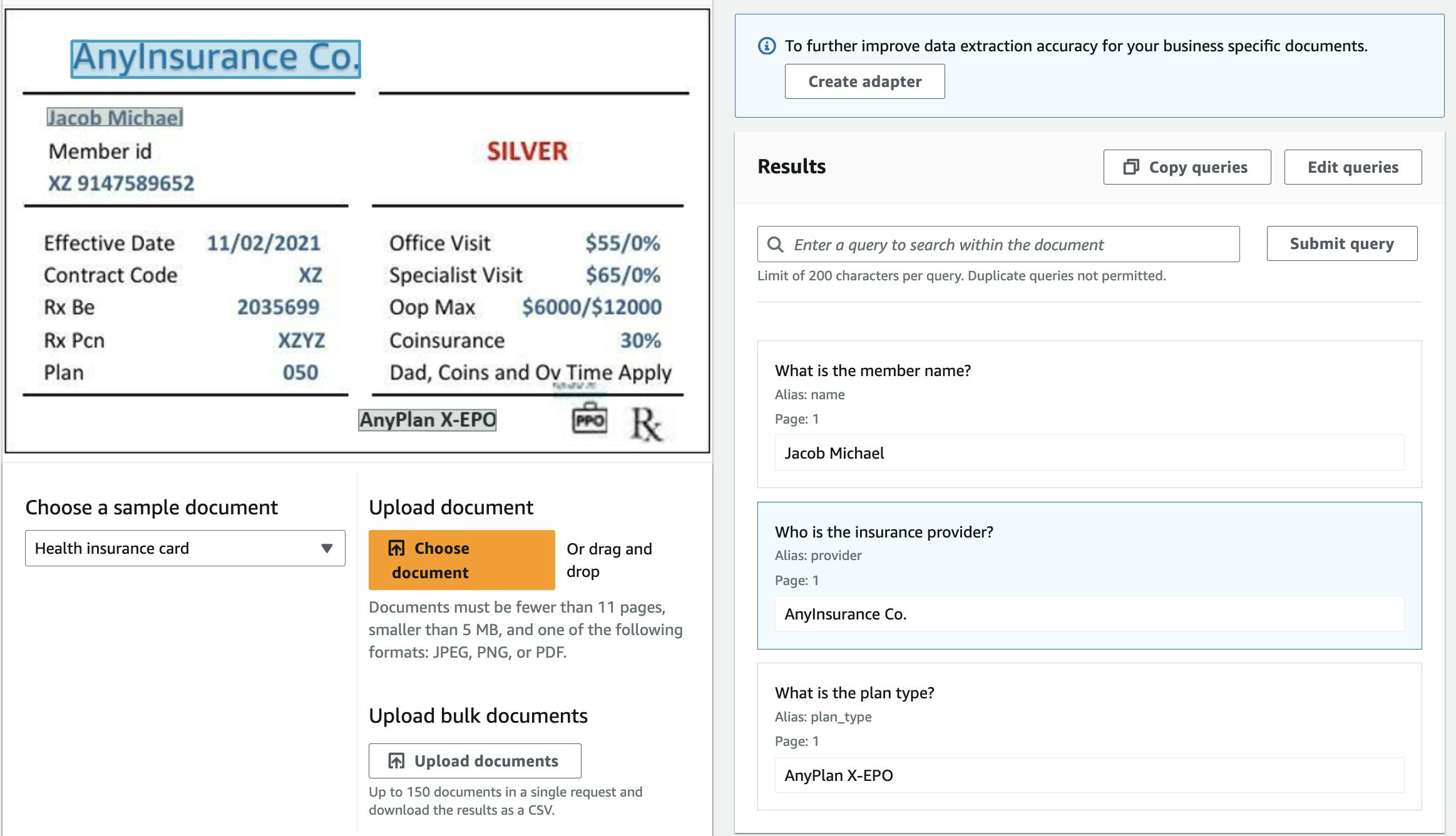
In the above image, you can find the health card on the left and the queries and their results on the right. Even it highlighted the parts containing the data in the health card. You can see a demo here

Below is the sample implementation of Textract as a service in Python
import boto3
class OCRService:
def __init__(self):
session = boto3.Session(region_name="ap-south-1",
aws_access_key_id="YOUR_AWS_ACCESS_KEY",
aws_secret_access_key="YOUR_AWS_SECRET_KEY")
self.client = session.client("textract", region_name="ap-south-1")
def parse_file_s3url(self, file_url: str):
if not file_url.startswith("s3://"):
raise ValidationError("File url should be s3 url.")
document_info = file_url.split('s3://')[1].split('/')
if len(document_info) < 2:
raise ValidationError("Invalid file path")
bucket_name = document_info[0]
file_path = '/'.join(document_info[1:])
return bucket_name, file_path
def analyse_doc_using_textract(self, bucket_name: str, file_path: str, queries: tuple | list[str]):
response = self.client.analyze_document(
Document={'S3Object': {'Bucket': bucket_name, 'Name': file_path}},
FeatureTypes=["QUERIES"], QueriesConfig={'Queries': [
{'Text': '{}'.format(query)} for query in queries
]})
return response
def _format_response(self, response: Any):
# The response structure is https://boto3.amazonaws.com/v1/documentation/api/latest/reference/services/textract/client/analyze_document.html#
results = {}
if "Blocks" not in response:
return {}
for block in response['Blocks']:
if block['BlockType'] == "QUERY":
res_id = block.get('Relationships', [{"Ids": [""]}])[0]['Ids'][0]
if res_id in results:
results[res_id]["query"] = block["Query"]["Text"]
else:
results[res_id] = {
"query": block["Query"]["Text"]
}
elif block['BlockType'] == "QUERY_RESULT":
res_id = block["Id"]
if res_id in results:
results[res_id]["result"] = block["Text"]
results[res_id]["confidence"] = block["Confidence"]
else:
results[res_id] = {
"result": block["Text"],
"confidence": block["Confidence"]
}
"""
results = {
'3cd4fe18-2bbe-4d7e-a2f5-7ebe89f2a9fe': {'query': 'What is the member name?', 'result': 'Jacob Michael', 'confidence': 100.0},
'eb4945e4-cd1f-4866-9ada-5ba10d50f86a': {'query': 'Who is the insurance provider?', 'result': 'AnyInsurance Co.', 'confidence': 86.0},
'4ed3b10b-ea84-424d-ad7d-3d38ea2fa91b': {'query': 'What is the plan type?', 'result': 'AnyPlan X-EPO', 'confidence': 85.0}
}
"""
all_query_results = results.values()
query_results = {}
for val in all_query_results:
query_results[val['query']] = {
"result": val.get("result", ""),
"confidence": val.get("confidence", 0)
}
return query_results
def _analyse_doc(self, file_url: str, queries=None):
if queries is None:
queries = []
bucket_name, file_path = self.parse_file_s3url(file_url)
response = self.analyse_doc_using_textract(bucket_name, file_path, queries)
return response
def analyse_health_card(self, file_url: str):
queries = (
"What is the member name?",
"Who is the insurance provider?"
"What is the plan type?"
)
res = self._analyse_doc(file_url, queries)
formatted_response = self._format_response(res)
return formatted_response
# usage
s3_file_url = 's3://bucket_name/file_path'
resp = OCRService().analyse_health_card(s3_file_url)
# sample response
{'What is the member name?': {'result': 'Jacob Michael', 'confidence': 100.0},
'Who is the insurance provider?': {'result': 'AnyInsurance Co.', 'confidence': 86.0},
'What is the plan type?': {'result': 'AnyPlan X-EPO', 'confidence': 85.0}}
As we need specific information from the document, we use queries. Based on the response structure of Textract’s analyze_document, we wrote the _format_response function that returns a simple dict.
The basic idea is that analyze_document returns a large response containing different data, which you can see here
For now, we are interested in the queries we have asked, so in the response, we need to check for the following block types:
QUERY - A question asked during the call of AnalyzeDocument. It contains an alias and an ID that attaches it to its answer
QUERY_RESULT - A response to a question asked during the call of AnalyzeDocument. It comes with an alias and ID for ease of locating in a response. It also contains location and confidence scores
We separate the data using the ID for block types QUERY/QUERY_RESULT, then we save the query text (the question), text (the result), and the confidence of that result.
Conclusion
In the realm of AI, no system is flawless. Despite its impressive capabilities, OCR technology can occasionally produce inaccuracies or false data. Therefore, it's vital to approach OCR implementation with caution and awareness of its limitations.